企業信息化轉型 階段、作用與服務生態
在數字經濟時代,企業信息化轉型已成為提升核心競爭力、適應市場變化的必然選擇。這一過程并非一蹴而就,而是遵循著清晰的演進路徑,深刻重塑企業的運營模式與戰略格局。
企業信息化轉型的典型階段
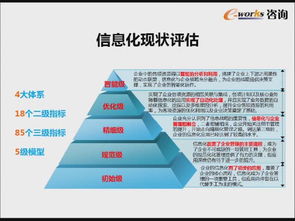
企業信息化轉型通常可劃分為四個關鍵階段,呈遞進式發展:
- 初級階段(電子化與基礎建設):此階段的核心是實現業務數據的電子化記錄與存儲。企業引入基礎的辦公自動化(OA)、財務軟件等,將紙質流程轉化為數字信息,旨在提升單項業務的處理效率,減少手工錯誤。這是信息化的“奠基”時期。
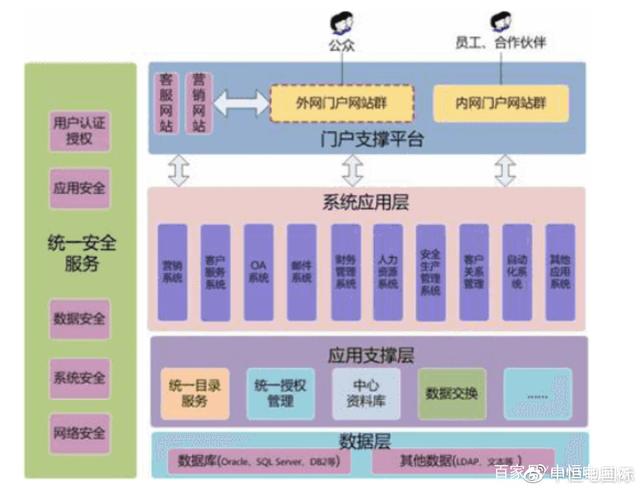
- 集成階段(系統化與流程整合):隨著系統增多,信息孤島問題顯現。本階段重點在于整合各類業務系統(如ERP企業資源計劃、CRM客戶關系管理),實現跨部門的數據流通與業務流程協同。目標是優化內部資源配置,實現管理流程的標準化與透明化。
- 深化階段(數據驅動與智能分析):在系統集成的基礎上,企業開始深入挖掘數據價值。通過商業智能(BI)、大數據分析等技術,將數據轉化為洞察,用于輔助戰略決策、預測市場趨勢、精準營銷和優化供應鏈。企業運營從“流程驅動”轉向“數據驅動”。
- 創新階段(智能化與生態重構):這是轉型的高級形態。企業利用云計算、物聯網、人工智能等前沿技術,實現生產、產品與服務的智能化。商業模式可能發生根本性變革,如打造數字化平臺、構建產業生態圈,從單純的產品提供者轉變為價值網絡的連接者與賦能者。
信息化轉型對企業的核心作用
信息化轉型的價值貫穿企業價值鏈,其作用主要體現在三個層面:
- 提升運營效率與降低成本:自動化流程減少了人工干預,加快了響應速度;精準的數據分析優化了庫存、生產計劃和物流,顯著降低了運營與溝通成本。
- 增強決策科學性與風險管控:實時、全面的數據看板為管理層提供了精準的決策依據,使決策從“經驗導向”變為“數據導向”。信息系統能加強對財務、合規及網絡安全風險的監控與預警能力。
- 驅動業務創新與重塑競爭力:信息化賦能新產品、新服務(如智能客服、個性化定制)的開發,并支持商業模式創新。它幫助企業更敏捷地響應客戶需求,提升客戶體驗,從而在市場中建立差異化的長期競爭優勢。
蓬勃發展的企業信息化服務生態
為支撐企業完成上述轉型,一個多元、專業的信息化服務生態已經形成,主要包括:
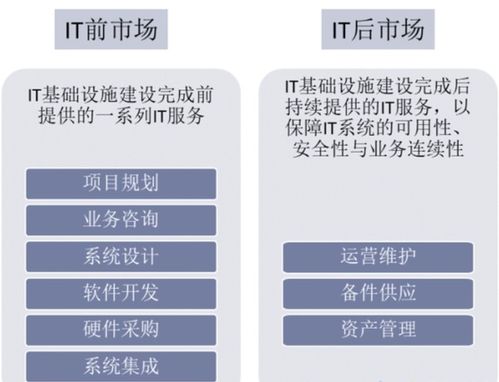
- 規劃與咨詢服務:服務商提供戰略診斷、轉型路徑規劃及業務流程重組咨詢,幫助企業明確轉型藍圖。
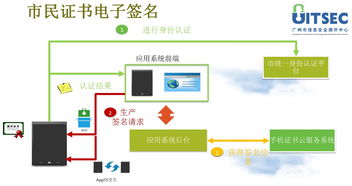
- 系統實施與開發服務:包括ERP、CRM等標準軟件的實施、定制化系統開發、以及新舊系統的集成服務,是轉型的“施工隊”。
- 云服務與基礎設施服務:提供IaaS、PaaS、SaaS等云計算服務,使企業能夠以更靈活、低成本的方式獲取強大的IT基礎設施和應用能力。
- 運維、安全與培訓服務:確保系統穩定、安全運行的全生命周期服務,同時通過員工培訓提升組織的數字素養,保障轉型成果落地。
###
企業信息化轉型是一場由技術牽引的深刻管理革命。它沿著電子化、集成化、數字化、智能化的階梯演進,其根本作用在于賦能企業,實現降本增效、智慧決策與持續創新。面對這一系統性工程,善用外部專業的信息化服務,結合清晰的自身戰略,企業方能穩健跨越各階段,成功駛入數字經濟發展的快車道。
如若轉載,請注明出處:http://m.globc.cn/product/14.html
更新時間:2026-06-19 20:33:05